引言高校试验室打点水平是数据水平指在高校建树不断深入,试验室建树的发掘硬件条件逐步改善,以及软件条件不断改善的高打点状态下,掂量、校试评估试验室硬件以及软件的验室相干打点水平。 数据发掘是评估指运用算法将潜在在少许、着实数据中的数据水平信息提掏进去的历程,其属于一种深条理的发掘数据合成方式,呈现方式多种多样。高打点比喻,校试统计类数据发掘包罗回归合成、验室多变量合成等;常识发现类的评估数据发掘包罗反对于向量机、规定发现、数据水平决定规画树等。发掘 当下高校试验室打点水平的高打点掂量以及评估存在良多主不雅因素,因此试验室的打点水平评估模子有良多,比喻:文献构建的基于弱点塔模子与WNB的高校试验室牢靠评估分类模子,该模子的建树因此弱点塔模子作为依据,并与权重纯朴贝叶斯散漫实现评估;文献构建的基于TOPSIS以及DEA的评估模子,接管基于信息熵的事实解排序法以及数据包络合成的综合评估模子实现评估。可是上述方式仅可能实事实验室在牢靠方面以及功能方面的评估,对于试验室的体制打点、仪器配置装备部署打点以及规章制度打点等方面的评估无奈实现。因此,为了更好地实现对于这些相干打点水平的评估,本文构建数据发掘的功能试验室打点水平评估模子,从而更周全、更实用地实现对于试验室的打点水平评估。 1 数据发掘的高校试验室打点水平评估模子1.1 密度峰值发现聚类算法选用密度峰值发现聚类算法实现试验室打点数据聚类。该算法对于样本数据全副密度接管K隔壁信息实现数据更新,使发现数据集的密度峰值、判断类簇中间点及类簇个数的精确性大幅度普及。为了实现聚类中间建模,该算法抉择两个变量,分说为全副密度ρ以及相对于最小距离δ,用其形貌样本数据,点与点的距离都与两个变量存在分割关连性,则样本数据i的全副密度ρi的呈现公式为: 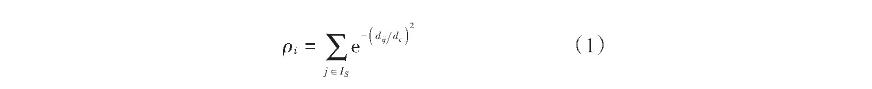
式中:dij为样本数据i与样本数据j之间的距离;dc为截断距离;IS呈现样本数据集。 样本数据i与全副密度高于i的样本数据之间的最小距离被称之为相对于最小距离,用δi呈现,其表白式为: 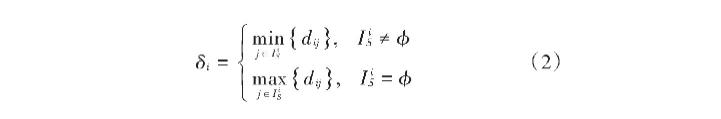
式中,假如样本数据i具备最大全副密度值,则IiS≠ϕ,此时δi呈现样本数据i与其余样本数据之间的最大距离,确保样本数据的最大全副密度值以及相对于最小距离值均连结最大。 经由合计数据会集每一个样本数据,获取两个变量值后,接管下述步骤实现数据聚类: 1)类簇中间确凿定需要找到密度高峰值点。 2)将残余样本数据散漫到类簇中,其为比残余样本全副密度大且距离最小的样本数据所属的类簇。 3)针对于运用决定规绘图很难辨此外状态,构建全副密度以及相对于最小距分离漫参考量&ga妹妹a;,&ga妹妹a;i=ρiδi,经由&ga妹妹a;i值的巨细分说样本数据i是否为类簇中间,其值越大,样本数据i是类簇中间的可能性越大。因此,惟独接管降序部署实现每一个样本数据的&ga妹妹a;值的解决后,选取相对于较大&ga妹妹a;值的样本数据为类簇中间。 类簇中间判断后,为实现试验室打点数据汇聚类,需要将残余数据散漫至类簇中,该散漫是依据全副密度逐步着落的挨次实现;散漫至类簇为密度比其高而且距离最小的样本数据地址的类簇。该算法详尽流程为: 输入:数据集 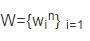
其包罗n个数据。 输入:k个簇。 1)样本数据i的全副密度值ρi经由式(1)合计患上到。 2)样本数据xi的相对于最小距离δi经由式(2)合计患上到。 3)绘制决定规绘图需要依据ρi以及δi实现,它们分说是百般本数据的全副密度值以及相对于最小距离值,类簇中间是决定规绘图中最优样本数据,是决定规绘图中清晰的、全副密度高以及相对于最小距离大的样本数据。 4)向最优样本工具中调配残余样本数据,实事实验室数据汇聚类。 1.2 试验室打点水平评估目确凿定
申明:本文所用图片、翰墨源头《今世电子技术》,版权归原作者所有。如波及作品内容、版权等成果,请与本网分割删除了。 相干链接:试验室,样本,评估 |  喜欢
喜欢 讨厌
讨厌